Numerisk derivasjon#
Læringsutbytte
Etter å ha arbeidet med denne delen av emnet, skal du kunne:
forklare den teoretisk bakgrunnen for numerisk derivasjon, og forskjellen på numerisk og analytisk derivasjon
implementere framoverdifferansen, bakoverdifferansen og sentraldifferansen for numerisk derivasjon
derivere funksjoner og eksperimentelle data
Derivasjonsbegrepet#
Derivasjon handler om endring. Den deriverte kan beskrive stigningen og forandringen i et forløp. Nærmere bestemt handler det om momentan endring, altså endringen mellom to tilstander (funksjonsverdier) over en svært liten endring i en annen tilstand:
Vi har derfor nytte av derivasjon i mange tilfeller der vi ønsker å beskrive en utvikling, og det er ikke sjeldent i kjemi. Tenk for eksempel på følgende scenarioer:
Vi ønsker å finne ekvivalenspunktet i en titrering. Det er der endringen (den deriverte) er størst.
Vi ønsker å finne maksimum og minimum energi til et molekyl. Ekstremalpunkter er der den deriverte er lik 0.
Vi ønsker å finne ut av hvordan konsentrasjon endrer seg med tid for hvert minste tidssteg. Dette kan representeres som \(dc/dt\).
Vi kan derimot ikke alltid derivere analytisk for hånd, så det er en stor verdi i å beherske numerisk derivasjon. Da kan vi enklest tilnærme den analytisk deriverte med en numerisk derivert:
Numerisk derivasjon (framoverdifferansen)
For en liten verdi av \(dx\) kan vi tilnærme den førstederiverte slik:
der vi tilnærmer grenseverdien med en svært liten verdi av dx. Her skal vi se på denne metoden og andre metoder som kan brukes til å tilnærme den deriverte numerisk.
Underveisoppgave
Bruk definisjonen ovenfor og regn ut \(f'(1)\) for \(f(x) = 2x + 2\). Sett \(dx = 1\cdot 10^{-8}\).
Løsningsforslag
def f(x):
return x**2
dx = 1E-8
x = 1
fder = (f(x + dx) - f(x))/dx
print("f'(1) =", fder)
Løsningsforslaget ovenfor viser en enkel måte å implementere den numeriske deriverte på. Det kan også være nyttig å kunne lage metoden som en funksjon:
def deriver(f, x, dx = 1E-8):
dy = f(x + dx) - f(x)
return dy/dx
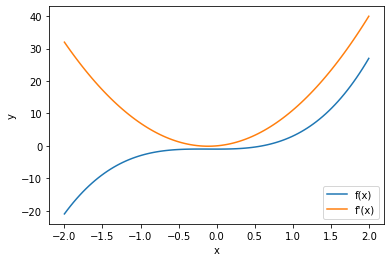
Legg merke til at vi ikke deriverer symbolsk. Det betyr at vi ikke får en annen funksjon når vi deriverer en funksjon. Vi får bare funksjonsverdier. Vi må altså deriverere i gitte punkter, for eksempel \(f'(1)\) eller \(f'(-5)\). Dersom vi ønsker å visualisere den deriverte til en funksjon, må vi derfor derivere funksjonen i flere punkter. Dette kan vi gjøre vektorisert ved hjelp av arrayer:
import numpy as np
import matplotlib.pyplot as plt
def f(x):# Definerer en funksjon vi skal derivere
return 3*x**3 + x**2 - 1
x = np.linspace(-2,2,100)
y = f(x)
yder = deriver(f,x)
plt.plot(x,y,label="f(x)") # Plotter funksjonen
plt.plot(x,yder,label="f'(x)") # Plotter den deriverte funksjonen
plt.xlabel("x")
plt.ylabel("y")
plt.legend()
plt.show()
Feilanalyse#
La oss nå ta en titt på hvilke verdier av \(\Delta x\) som gir best resultat. Det må vel være den verdien som ligger nærmest 0, altså en så liten verdi som mulig – eller? La oss teste dette ved å skrive ut den deriverte for ulike verdier av \(\Delta x\):
def f(x):
return 2*x**2 + x - 5
def fder_analytisk(x):
return 4*x + 1
x = 1
delta_x = [10**-i for i in range(1,18)] # liste med verdier fra 10^-18 til 10^-1
analytisk = fder_analytisk(x)
for i in range(len(delta_x)):
numerisk = deriver(f, x, delta_x[i])
feil = abs(numerisk-analytisk)/analytisk * 100
print("For delta_x =", delta_x[i],"er feilen:", feil, "%")
For delta_x = 0.1 er feilen: 4.000000000000092 %
For delta_x = 0.01 er feilen: 0.40000000000048885 %
For delta_x = 0.001 er feilen: 0.03999999998569592 %
For delta_x = 0.0001 er feilen: 0.003999999920267783 %
For delta_x = 1e-05 er feilen: 0.00040000068821655077 %
For delta_x = 1e-06 er feilen: 3.999977025159751e-05 %
For delta_x = 1e-07 er feilen: 4.010780685348436e-06 %
For delta_x = 1e-08 er feilen: 6.07747097092215e-07 %
For delta_x = 1e-09 er feilen: 8.274037099909037e-06 %
For delta_x = 1e-10 er feilen: 8.274037099909037e-06 %
For delta_x = 1e-11 er feilen: 8.274037099909037e-06 %
For delta_x = 1e-12 er feilen: 0.008890058234101161 %
For delta_x = 1e-13 er feilen: 0.07992778373591136 %
For delta_x = 1e-14 er feilen: 0.524016993585974 %
For delta_x = 1e-15 er feilen: 6.581410364015028 %
For delta_x = 1e-16 er feilen: 100.0 %
For delta_x = 1e-17 er feilen: 100.0 %
Vi ser at “store” verdier som 0.1 og 0.01 gir en del feil. Men vi ser også faktisk at nøyaktigheten er størst ved \(dx = 10^{-8}\), og at den synker både med økende og med minkende \(dx\). Og attpåtil gir \(dx \leq 10^{-16}\) null som svar! Dette gir naturlig nok en feil på 100 %, siden den analytiske verdien er 5.
Vi forventer kanskje ikke dette resultatet. Dersom vi kun ser på definisjonen av den deriverte, er det ikke spesielt logisk at det skal slå slik ut. Men det hele handler om at tall ikke er representert eksakt i en datamaskin, og når datamaskinen skal operere med svært små tall, kan det bli en liten avrundingsfeil når den regner med tallene. Denne avrundingsfeilen gjør at vi får feil dersom vi velger for små verdier av \(dx\). Dersom vi gjør en mer generell feilanalyse, viser det seg at \(10^{-8}\) er en god verdi å velge her.
Underveisoppgave
Lag et plott med feilen som funksjon av dx med utgangspunkt i programmet ovenfor. Bruk logaritmiske akser – dette får resultatene tydeligere fram. Du kan lage logaritmiske akser slik:
plt.yscale('log')
plt.xscale('log')
Løsningsforslag
import matplotlib.pyplot as plt
def f(x):
return 2*x**2 + x - 5
def fder_analytisk(x):
return 4*x + 1
x = 1
delta_x = [10**-i for i in range(1,18)] # liste med verdier fra 10^-18 til 10^-1
analytisk = fder_analytisk(x)
avvik = []
for i in range(len(delta_x)):
numerisk = deriver(f, x, delta_x[i])
feil = abs(numerisk-analytisk)/analytisk * 100
avvik.append(feil)
print("For delta_x =", delta_x[i], "er feilen:", feil, "%")
plt.plot(delta_x, avvik)
plt.yscale('log')
plt.xscale('log')
plt.xlabel('dx')
plt.ylabel('Feil (%)')
plt.show()
Andre tilnærminger#
Tilnærmingen til den deriverte som vi har sett på, tar utgangspunkt i punktene \((x, f(x))\) og \((x+dx, f(x+dx))\) for å regne ut den momentane vekstfarten (altså den deriverte) i punktet \(x\). Men vi kan like godt bruke andre punkter. Metoden vi har sett på, kalles framoverdifferansen fordi den tar utgangspunkt i punktet \(x\) og neste punkt \(x + dx\). Tilsvarende kan vi ta utgangspunkt i punktet \(x\) og forrige punkt \(x - dx\). Dette kaller vi bakoverdifferansen. Bakoverdifferansen gir samme feil som framoverdifferansen, men er teoretisk nyttig for å utlede andre metoder.
Numerisk derivasjon (bakoverdifferansen)
For en liten verdi av \(dx\) kan vi tilnærme den førstederiverte slik:
En metode som derimot gir mindre feil enn både framover- og bakoverdifferansen, er sentraldifferansen. Det er en slags kombinasjon av framover- og bakoverdifferansen, der vi tar utgangspunkt i gjennomsnittet (midtpunktet) av \(x+dx\) og \(x-dx\).
Numerisk derivasjon (sentraldifferansen)
For en liten verdi av \(dx\) kan vi tilnærme den førstederiverte slik:

Underveisoppgave
Implementer bakover- og sentraldifferansen som Python-funksjoner. Gjør en feilanalyse med de tre ulike tilnærmingene for ulike verdier av \(\Delta x\). Bruk funksjonen \(f(x) = \sin{(x)}\) og sammenlikn med den analytiske verdien av den deriverte, \(f'(x) = \cos{(x)}\)
Numerisk derivasjon av data#
Nå kommer vi til den nyttigste delen av numerisk derivasjon, nemlig derivasjon av diskrete data. Vi kan derivere på samme måte som vi gjorde med kontinuerlige funksjoner, men vi har gitt en \(dx\) som er gitt av avstanden mellom datapunktene våre. Hvis målefrekvensen er lav, blir \(dx\) høy, og motsatt. La oss se på hvordan vi kan derivere en titrerkurve:
import pandas as pd
# Leser og sjekker ut dataene
data = pd.read_csv("https://raw.githubusercontent.com/andreasdh/programmering-i-kjemi/master/docs/datafiler/titreringsdata.txt")
data.head()
| volum | pH | |
|---|---|---|
| 0 | 0.00 | 2.51 |
| 1 | 2.05 | 2.76 |
| 2 | 4.00 | 3.03 |
| 3 | 6.01 | 3.11 |
| 4 | 8.22 | 3.31 |
# Plotter dataene
import matplotlib.pyplot as plt
x = data["volum"]
y = data["pH"]
plt.scatter(x, y)
plt.title("Titrering av eddiksyre med NaOH")
plt.xlabel("Volum tilsatt NaOH (mL)")
plt.ylabel("pH")
plt.show()

I en titrering er vi ofte ute etter ekvivalenspunktet, altså der stoffmengden av analytt og titrant er ekvivalente. Ekvivalenspunktet ligger der endringen i pH er brattest, altså der den deriverte \(\frac{dpH}{dV}\) er størst. Vi har ikke noe uttrykk å derivere, men vi kan tilnærme den deriverte med en numerisk derivert. Siden vi ikke kan sette \(dx\) til en bestemt verdi, blir ikke tilnærmingen særlig god hvis vi har målt sjeldent. Forskjellen i x-verdi er nemlig gitt av målingene (her er \(dV\) antall mL som blir tilsatt hver gang vi måler pH). Men selv i tilfeller der tilnærmingen ikke er god, kan vi si noe om den gjennomsnittlige endringen mellom to punkter. La oss derivere:
dydx = []
for i in range(len(y)-1):
dy = y[i+1]-y[i]
dx = x[i+1]-x[i]
der = dy/dx
dydx.append(der)
dydx.append(None)
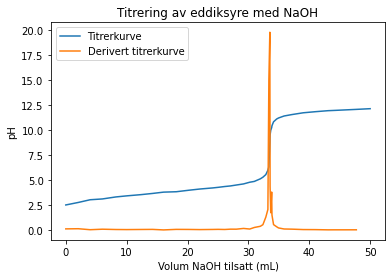
plt.plot(x, y, label='Titrerkurve')
plt.plot(x, dydx, label='Derivert titrerkurve')
plt.title('Titrering av eddiksyre med NaOH')
plt.xlabel('Volum NaOH tilsatt (mL)')
plt.ylabel('pH')
plt.legend()
plt.savefig('derivert_titrering.pdf')
plt.show()
I løkka bruker vi samme framgangsmåte som vi gjorde da vi deriverte funksjoner, men nå tar vi verdiene fra ei liste med verdier. Vi kan kun kjøre løkka til lengden av lengden av listene minus 1, fordi vi skal ta forskjellen mellom verdier. Da blir det nemlig én verdi mindre enn i y- og x-listene. Derfor legger vi til en ekstra verdi “None” til slutt i lista, slik at alle listene blir like lange.
Vi ser tydelig at det er størst endring i ekvivalenspunktet. Vi kan finne hvilket volum dette tilsvarer slik:
data["endring"] = dydx # Legger dydx inn i dataframen
ekvivalenspunktet = data[data["endring"] == data["endring"].max()]
ekvivalenspunktet.head()
| volum | pH | endring | |
|---|---|---|---|
| 25 | 33.52 | 8.7 | 19.75 |
print("Ekvivalenspunktet ble nådd ved tilsats av", float(ekvivalenspunktet["volum"]), "mL 0.10 M NaOH.")
Ekvivalenspunktet ble nådd ved tilsats av 33.52 mL 0.10 M NaOH.
Som du ser, kan vi benytte numerisk derivasjon på både kontinuerlige funksjoner og diskrete data. Hovedpoenget er at vi finner ut noe om endringen i en funksjon eller i et datasett. Og desto mindre dx er, desto bedre tilnærming er denne endringen til den momentante endringen i et punkt, altså den deriverte.
Oppgaver#
Oppgave 1
Beregn f’(1) numerisk for følgende funksjoner. Kontroller ved å derivere for hånd.
\(f(x) = x^2 - 4x + 5\)
\(f(x) = e^x\)
\(f(x) = \sqrt{\ln(x)}\)
Oppgave 2
Skriv om funksjonen deriver slik at dx har en standardverdi. Velg en standardverdi som sannsynligvis vil gi gode resultater.
def deriver(f, x, dx = 1E-8):
dy = f(x + dx) - f(x)
return dy/dx
Oppgave 3
En partikkel følger posisjonsfunksjonen \(x(t) = t^3 + \frac{1}{3}\cdot t\). Plott både posisjon, hastighet og akselerasjon for \(t = [0,10]\). Husk at \(v(t) = s'(t)\) og \(a(t) = v'(t)\).
Oppgave 4
Forklar hva som er forskjellen mellom analytisk og numerisk derivasjon.
Oppgave 5
Temperaturen \(T(t)\) (i celsius) etter \(t\) minutter til en nylig lagd te følger denne modellen, som vi har kommet fram til ved regresjon av eksperimentelle data:
a) Bruk Newtons kvotient for å tilnærme den deriverte til \(T(t)\) for 1000 jevnt fordelte verdier av \(t\) i intervallet \([0, 60]\) b) Plott resultatet fra a) sammen med grafen for \(T(t)\). Bruk merkelapper (labels og legend) for grafene. c) Hvor mye synker temperaturen med ved element nr. 42 i lista over verdier for \(t\) (vi teller med 0-te element)?
Oppgave 6
Programmet nedenfor leser av fila “heistur_kjemi_fysikk.txt” og finner fart og akselerasjon ved hjelp av numerisk derivasjon. Programmet fungerer derimot ikke helt som det skal. Rett opp feilen. Lag også en ny kolonne “fart” og en ny kolonne “akselerasjon” i dataframen.
Løsningsforslag
import pandas as pd
import matplotlib.pyplot as plt
data = pd.read_csv("heistur_kjemi_fysikk.txt")
p = data["height_m"]
t = data["time_s"]
v = [] # fart i m/s
a = [] # akselerasjon i m/s^2
# Vi trenger to løkker fordi a tar utgangspunkt i v, som derfor må lages først
for i in range(len(p)-1):
dt = t[i+1] - t[i]
fart = (p[i+1] - p[i])/dt
v.append(fart)
for i in range(len(v)-1):
dt = t[i+1] - t[i]
akselerasjon = (v[i+1] - v[i])/dt
a.append(akselerasjon)
v.append(None)
a.append(None)
a.append(None)
# Legger til verdiene i dataframen
data["fart"] = v
data["akselerasjon"] = a
plt.subplot(3,1,1)
plt.ylabel("Posisjon (m)")
plt.plot(t, p, color = "limegreen")
plt.subplot(3,1,2)
plt.ylabel("Fart (m)")
plt.ylim(-1,1)
plt.plot(t, v, color = "navy")
plt.subplot(3,1,3)
plt.ylabel("Akselerasjon (m)")
plt.plot(t, a, color = "firebrick")
plt.ylim(-1,1)
plt.xlabel("Tid (s)")
plt.tight_layout()
plt.show()
Oppgave 7
Løs puslespillet nedenfor, som skal illustrere derivasjon av diskrete data.