Datavisualisering#
Læringsutbytte
Etter å ha arbeidet med dette temaet, skal du kunne:
bruke matplotlib-biblioteket til visualisering
plotte datapunkter fra lister og filer
lage og tolke ulike visualiseringer
Kjemi er et eksperimentelt fag, og det er viktig å kunne generere informative figurer som beskriver eksperimentelle data på en god måte. Det blir stadig vanligere å bruke programmering til dette. Det finnes flere typer biblioteker som kan gi oss fine og profesjonelle figurer. Vi begynner med et mye brukt bibliotek som heter matplotlib.
Plotting av lister#
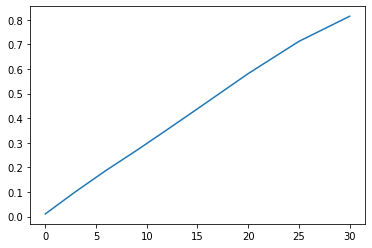
Hvis vi har få datapunkter, kan vi skrive dem inn i lister direkte i programmet vårt og plotte dem. La oss ta et eksempel der vi har målt absorbansen til et enzym med et spektrometer. Vi har fått følgende data:
tid (min) |
absorbans |
|---|---|
0 |
0.011 |
3 |
0.102 |
6 |
0.188 |
9 |
0.269 |
12 |
0.353 |
15 |
0.438 |
20 |
0.581 |
25 |
0.712 |
30 |
0.814 |
Dette kan vi plotte enkelt slik:
import matplotlib.pyplot as plt
t = [0, 3, 6, 9, 12, 15, 20, 25, 30] # Tid i min
A = [0.011, 0.102, 0.188, 0.269, 0.353, 0.438, 0.581, 0.712, 0.814] # Absorbans
plt.plot(t,A) # Plotter A mot t
plt.show() # Viser plottet
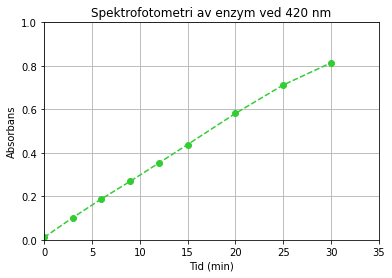
Hvis vi har lyst til å modifisere og pynte på plottet, har vi mange muligheter til det. Her er noen forslag til en del nyttige endringer av plottet ovenfor:
plt.plot(t,A,color="limegreen",marker="o",linestyle="--")
plt.title("Spektrofotometri av enzym ved 420 nm") # Tittel på plottet
plt.xlabel("Tid (min)") # Aksetittel på x-aksen
plt.ylabel("Absorbans") # Aksetittel på y-aksen
plt.xlim(0,35) # Definisjonsmengde
plt.ylim(0,1) # Verdimengde
plt.grid() # Lager rutenett
plt.show()
Det finnes utrolig mange måter å modifisere et plott på. Tabellene nedenfor viser en oversikt over nyttige plottekommandoer, linjestiler, markører og farger, som du kan bruke for å lage akkurat den figuren du ønsker. Du bør også søke litt rundt på nettet for å finne andre muligheter, for eksempel ved å søke på «python plotting colors» og liknende. Du må bruke internett flittig når du lurer på noe i programmering!
En veldig nyttig kommando når vi skal representere flere grafer i samme koordinatsystem, er legend. Denne kommandoen viser merkelappene (“labels”) til de ulike plottene. Programmet nedenfor gir et eksempel på dette.
Underveisoppgave
Programmet nedenfor plotter miljøgifter i ulike organismer i to innsjøer. Studer programmet og eksperimenter med ulike verdier fra tabellen nedenfor.
plot(x,y) # plotter x mot y og trekker rette linjer mellom
scatter(x,y) # plotter kun punkter
show() # viser plottet
title("tittel") # tittel på plottet
xlabel("tekst") # x-aksetittel
ylabel("tekst") # y-aksetittel
xlim(fra, til) # definisjonsmengde
ylim(fra, til) # verdimengde
grid() # rutenett på
axhline(y=0, color='black') # x-akse
axvline(x=0, color='black') # y-akse
Inni plottekommandoen kan vi også legge til farger, linjestiler, markører, merkelapper og liknende:
plot(x,y,color="",marker="",linestyle="",label="")
Markør |
Forklaring |
|---|---|
“.” |
punkt |
“o” |
sirkel |
” ” (mellomrom) |
ingen markør |
“^” |
triangel opp |
“v” |
triangel ned |
“s” |
firkant |
“p” |
femkant |
Linjestil |
Forklaring |
|---|---|
“-” |
heltrukket linje |
“–” |
stipla linje (lange) |
“;” |
stipla linje (korte) |
“-.” |
stilpa linje (annenhver kort/lang) |
” ” (mellomrom) |
ingen linje |

Plotte funksjoner#
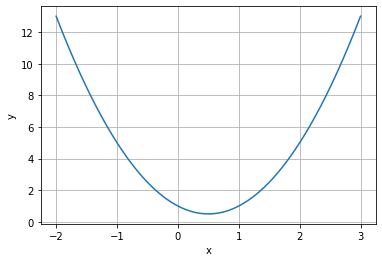
Hvis vi trenger å generere mange punkter, for eksempel for å plotte en funksjon, kan vi gjøre dette med kommandoen linspace, som genererer et visst antall (n) punkter mellom en verdi a og en verdi b. Den generelle syntaksen for dette er:
x = linspace(a, b, n)
Her lages det en array, noe som betyr at hvis vi gjør en matematisk operasjon på den, vil alle elementene påvirkes. Vi kan for eksempel mate arrayen inn i en funksjon. Da får en tilsvarende array med funksjonsverdier for alle verdier av x:
import matplotlib.pyplot as plt
import numpy as np
def f(x):
return 2*x**2 - 2*x + 1
x = np.linspace(-2, 3, 1000) # lager 1000 x-verdier mellom -2 og 3
y = f(x) # NB: Vi kan også skrive y = x*x**2 - 2*x + 1 uten å definere en funksjon!
plt.plot(x,y)
plt.xlabel('x')
plt.ylabel('y')
plt.grid()
plt.show()
Underveisoppgave
Plott tre funksjoner i samme koordinatsystem. Eksperimenter med farger, linjestiler og annet. Husk aksetitler!
Løsningsforslag
Underveisoppgave
Plott tre av dine favorittfunksjoner i samme koordinatsystem. Tilpass akser og tittel og pynt på plottet.
Datafiler#
Vi kan også visualisere data som er lagret i datafiler. Data lagres ofte i råtekstformat fordi de er robuste og kan leses av alle. Det betyr at dataene ikke har noen formatering eller annen informasjon enn de faktiske dataene. En Word-fil er for eksempel ikke råtekst, fordi den inneholder formatering av tekst som farger, kursivering og tekststørrelse. Eksempler på råtekstfiler er .txt-filer og .csv-filer. Råtekstdata kan vi lage manuelt, eller vi kan få dem fra sensorer eller laste dem ned fra internett. De fleste store datafiler lagres i råtekstformat.
Vi kan bruke Python til å lese slike data på mange ulike måter. Her skal vi bruke pandas-biblioteket til å lese filer, men du kan gjerne benytte andre framgangsmåter (som funksjonen loadtxt fra numpy). Vi tar utgangspunkt i en liten fil med få datapunkter, slik at det er enkelt å se hva som skjer når vi leser fila. Fila beskriver temperaturen i en kaffekopp (i \(^oC\)) med tida (i minutter), og ser slik ut:
tid (min), temperatur (grader celsius)
0,90
1,80
2,72
3,64
4,59
5,51
6,45
7,42
8,39
9,37
10,36
Vi ser at fila skiller datapunktene med komma, og at første linje som fungerer som overskrift. Dette er viktig informasjon når vi skal lese fila. For å lese en datafil, må den enten ligge i samme mappe som programmet som leser fila, eller så må du spesifisere hvilken filbane fila har. Det enkleste er å legge den i samme mappe som programmet, eller i en mappe som for eksempel heter “datafiler”, som ligger i samme mappe som programmet ditt.
Nedenfor ser du hvordan du kan lese fila med read_csv fra pandas og med loadtxt fra numpy. Du kan velge en av måtene å lese data på.
Et svært mye brukt bibliotek er Pandas-biblioteket. Det benyttes mye i datahåndtering og maskinlæring, og er kanskje den enkleste måten å lese filer på. Med funksjonen read_csv leses filer av typen .txt eller .csv, og vi får en ny datatype som kalles en dataramme (dataframe). En slik datatype kan ses på som en slags dictionary, der kolonneoverskriftene fungerer som nøkler. Dermed skriver vi data[“temperatur”] for å få tilgang til kolonnen med overskriften “temperatur”.
Pandas gir penest og ryddigst output dersom du bruker det i Jupyter Notebook. Vi skal bruke Pandas videre her, så da får du en smakebit på hva som er mulig.
Det finnes også en nyttig funksjon som heter loadtxt i numpy-biblioteket, som lar deg lese filer på en vektorisert måte uten løkker. Da lages det en array av dataene, med en array for hver kolonne inni denne arrayen. Arrayen er altså todimensjonal, og vi må derfor trekke ut de relevante kolonnene i hver sin endimensjonale array.
Her utfører vi “array-slicing”, det vil si at vi plukker ut elementer fra en todimensjonal array og lager en ny endimensjonal array av det.
Underveisoppgave
Kjør programmet nedenfor i Trinket-vinduet ovenfor. Hva viser programmet deg om array-slicing? Eksperimenter gjerne med å bytte ut verdiene, slik at du forstår hvordan verdiene plukkes ut
import numpy as np
import matplotlib.pyplot as plt
data = np.loadtxt("temperatur.txt", skiprows = 1, delimiter = ",") # Får to arrayer (kolonner) i en array
print(data)
t = data[0:3,0]
T = data[0:3,1]
print(t)
print(T)
plt.scatter(t, T)
plt.xlabel("Tid (s)")
plt.xlabel("Temperatur ($^o$C)")
plt.show()
Her leser vi data direkte fra en nettbasert editor (Trinket). Vi kan også lese ved å angi en nettadresse istedenfor et filnavn. Men hvis du har fila lagret lokalt på datamaskinen din, må du huske å legge den i samme mappe som programmet som skal lese fila (eller angi filbanen der fila ligger).